
This marks the primary such case in India, however the lack of clear insurance policies on AI’s use of public knowledge has sparked related conflicts globally. On the core of the problem is AI instruments’ relentless demand for high-quality knowledge. Nevertheless, their reliance on available on-line data is nearing its restrict. With out increasing their knowledge sources—equivalent to printed novels, private paperwork, movies, and copyrighted information content material—the expansion of AI chatbots might plateau.
This pursuit of knowledge, nonetheless, is colliding with copyright issues and the rigorously constructed enterprise fashions of publishers and media retailers.
Learn this | Mint Explainer: The OpenAI case and what’s at stake for AI and copyright in India
The story thus far
Within the US, publishers, musicians, and authors have taken authorized motion towards AI corporations for utilizing copyrighted content material to coach their fashions. Final 12 months, Getty Pictures sued Stability AI, accusing it of utilizing 12 million of its pictures to develop its platform. Equally, The New York Instances filed a lawsuit towards OpenAI, alleging the misuse of its content material and positioning the AI firm as a direct competitor in offering dependable data. A number of writers have additionally initiated lawsuits with related claims.
AI corporations, nonetheless, largely argue that their language fashions are constructed on publicly obtainable knowledge, which they contend is protected underneath truthful use coverage.
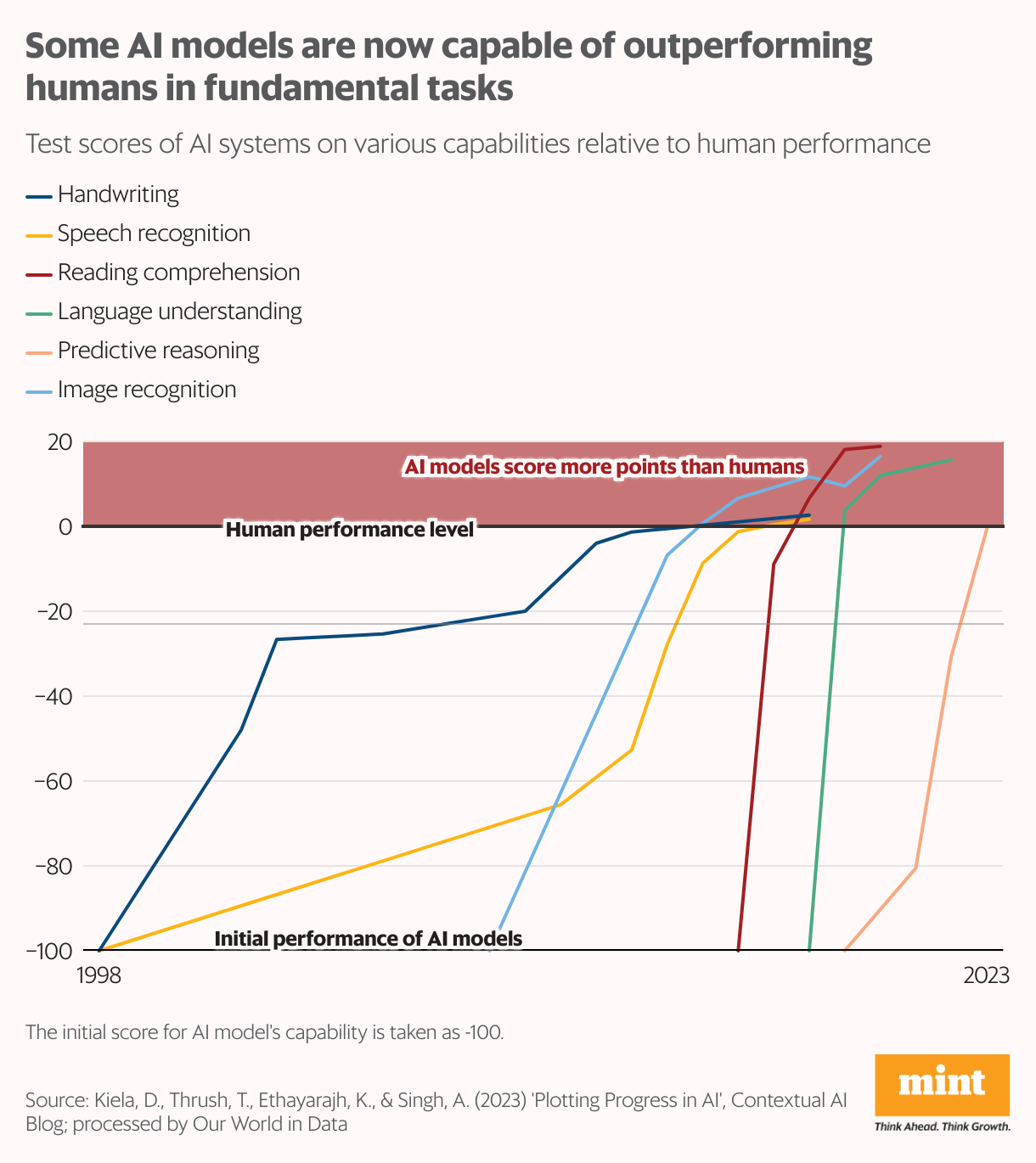
After being educated on huge datasets, superior AI fashions like OpenAI’s ChatGPT 4.0 and Google’s Gemini 1.0 Extremely have achieved computational effectivity corresponding to, if not surpassing, the human mind. A few of these fashions have even outperformed people in duties equivalent to studying, writing, predictive reasoning, and picture recognition.
Learn this | OpenAI vs ANI: Why ‘hallucinations’ are unlikely to go away quickly
To ship exact, error-free, and human-like outputs, AI methods require huge quantities of human-generated knowledge. Essentially the most superior fashions, equivalent to these two, are educated on trillions of phrases of textual content sourced from the web. Nevertheless, this pool of knowledge is finite, elevating questions on how these fashions will maintain their development as available data runs out.
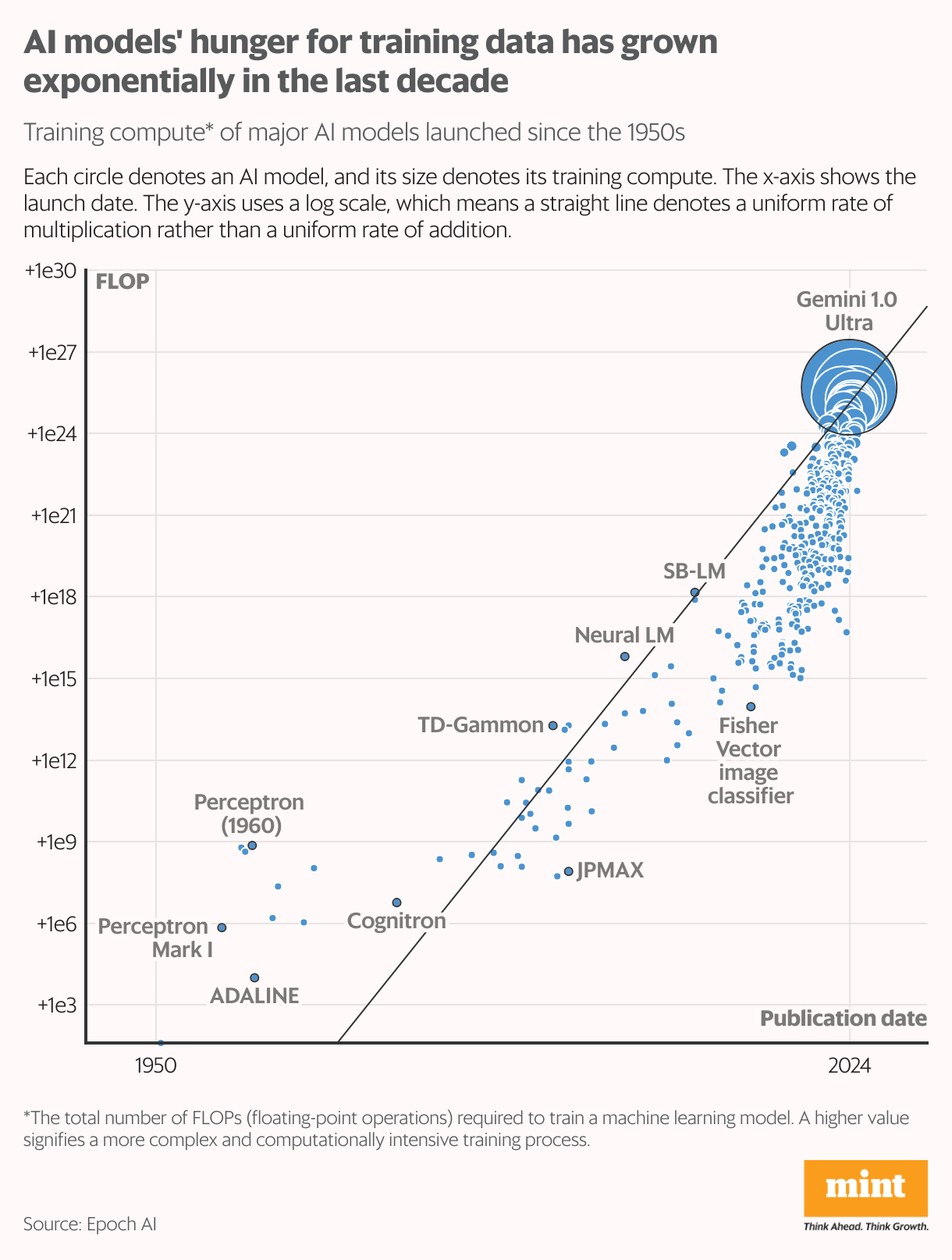
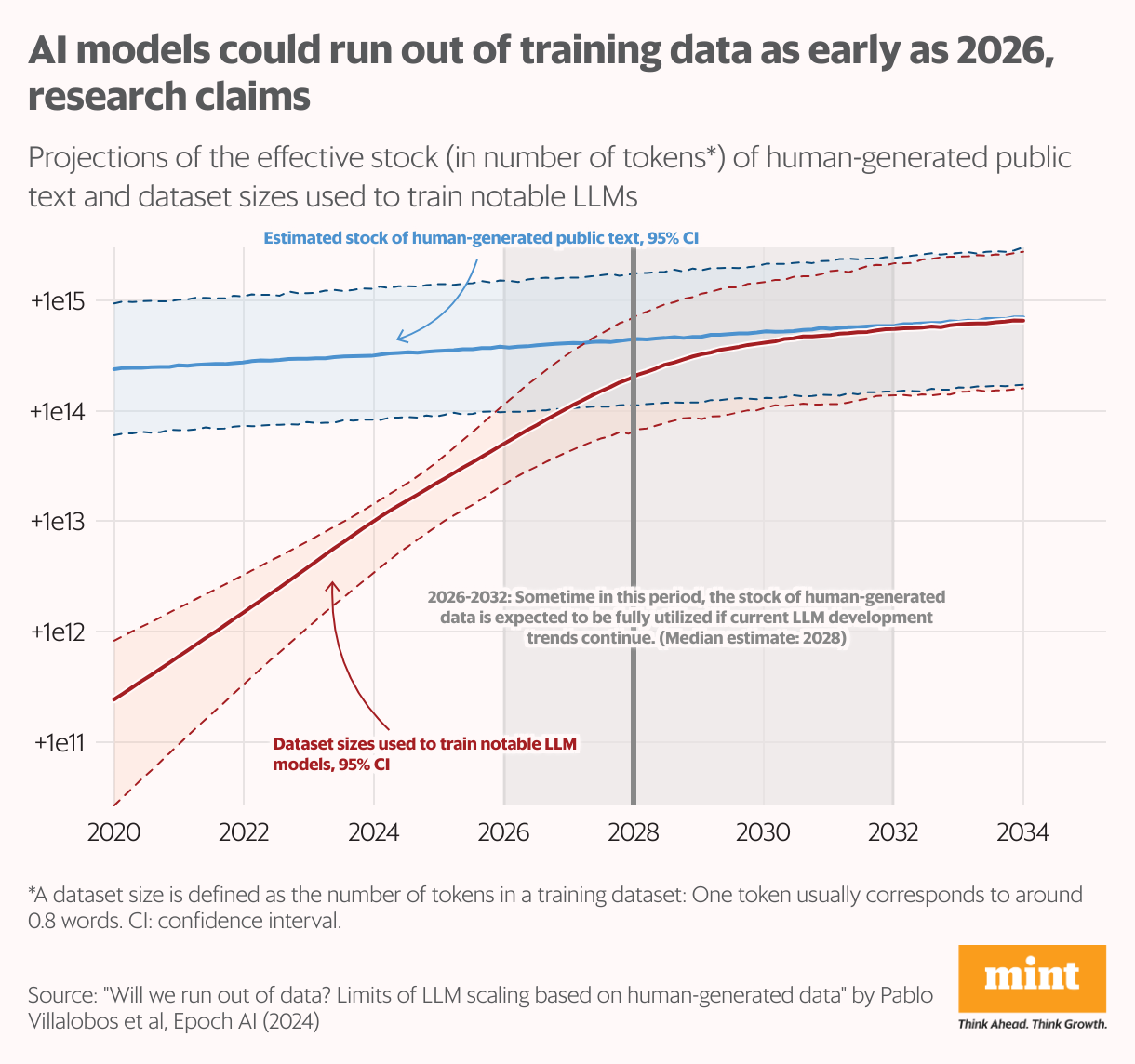
Researchers at Epoch AI estimate the web holds round 3,100 trillion “tokens” of human-generated knowledge—although solely about 10% is of enough high quality to coach AI fashions. (A token, on this context, is a elementary textual content unit, equivalent to a phrase, utilized by AI fashions for studying.) This stockpile is rising at a sluggish tempo, and as large-language fashions proceed to scale, they’re projected to exhaust this knowledge provide between 2026 and 2030, in line with an Epoch AI research printed earlier this 12 months.
OpenAI, going through a knowledge scarcity simply earlier than ChatGPT’s 2022 launch, turned to unconventional strategies. Based on a New York Instances report in April this 12 months, it created Whisper, a speech recognition instrument that transcribed thousands and thousands of hours of YouTube movies into textual content, doubtlessly breaching Google’s phrases and the rights of content material creators. Google itself allegedly did the identical, and expanded its privateness coverage to permit itself to faucet into recordsdata in Google Docs and Sheets to coach its bots.
The hunt
With knowledge in restricted provide, AI corporations are scouring each attainable supply to feed their fashions. College students’ assignments, YouTube movies, podcasts, on-line paperwork and spreadsheets, social media posts—nothing escapes the ravenous seek for knowledge by tech giants.
This relentless pursuit has fuelled fierce competitors amongst AI corporations to safe profitable knowledge offers with publishers, typically price thousands and thousands of {dollars}. As an example, Reddit struck a $60 million annual take care of Google, granting the tech big real-time entry to its knowledge for mannequin coaching. Legacy publishers like Wiley, Oxford College Press, and Taylor & Francis, in addition to information businesses equivalent to Related Press and Reuters, have additionally inked agreements with AI corporations, with some offers reportedly reaching multi-million-dollar valuations.
Additionally learn | Mint Explainer: What OpenAI o1 ‘reasoning’ mannequin means for the way forward for generative AI
As human-generated knowledge turns into more and more scarce and difficult to supply, AI corporations are turning to artificial knowledge—data created by AI fashions themselves, which may then be reused to generate much more AI knowledge. Based on analysis agency Gartner, artificial knowledge is projected to surpass human-generated knowledge in AI fashions by 2030.
Whereas artificial knowledge presents immense potential for AI corporations, it’s not with out dangers. A research printed in Nature in July 2024 by Ilia Shumailov and colleagues highlights the hazard of “mannequin collapse.” The analysis discovered that when AI fashions indiscriminately be taught from knowledge generated by different fashions, the output turns into vulnerable to errors. With every successive iteration, these fashions start to “mis-perceive” actuality, embedding delicate distortions that replicate and amplify over time. This suggestions loop may cause outputs to float farther from the reality, compromising the reliability of the fashions.
There have additionally been makes an attempt to enhance the algorithmic effectivity of AI fashions, which can enable them to be educated on a lesser quantity of knowledge for a similar output.
Small language fashions (SLMs), that are used for performing particular duties utilizing much less assets, have additionally turn out to be common as they assist AI corporations by not counting on huge troves of knowledge to coach their fashions. A working example, AI firm Mistral’s giant language mannequin 7B is constructed utilizing 7 billion parameters and the corporate claims it outperformed the LLM mannequin Meta’s Llama 2 constructed on 13 billion parameters on all benchmarks.
Additionally learn | India’s generative AI startups look past constructing ChatGPT-like fashions
The rat race of chatbots to outsmart one another—and the human mind—is shaping the way forward for know-how. As AI corporations grapple with knowledge shortage and copyright battles with publishers, the moral implications of their data-hungry pursuits are looming giant.
========================
AI, IT SOLUTIONS TECHTOKAI.NET